tekenset recente & trending topics
-
_ketter_
- Member

- Berichten: 68
- Lid geworden op: 20 dec 2008, 20:26
- Uitgedeelde bedankjes: 14 keer
- Bedankt: 2 keer
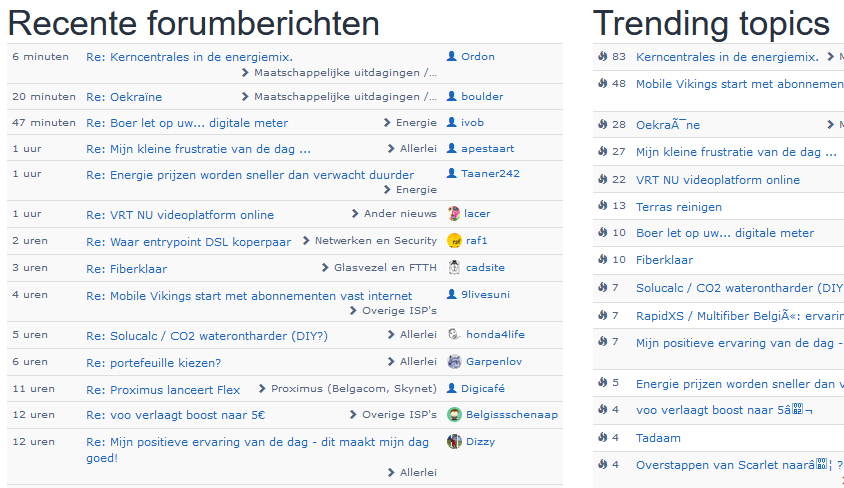
in het overzicht met recente forumberichten en trending topics wordt voor de trending topics lijst een verkeerde tekenset gebruikt, bv. Oekraïne en het euroteken € wordt verkeerd weergegeven. zie afbeelding.
- Bijlagen
-
- userbase2lijsten.png
- (50.77 KiB) Nog niet gedownload
so, a chicken is not a sparrow
-
devilkin

- Administrator

- Berichten: 6909
- Lid geworden op: 17 mei 2006, 20:10
- Uitgedeelde bedankjes: 1057 keer
- Bedankt: 663 keer
-
Provider
Ik vrees dat dat aan jouw browser/instellingen zal liggen...
Telenet All-Internet -- using CV8560E & OPNsense on PCEngines APU2E4
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)
-
devilkin
- Administrator
- Berichten: 6909
- Lid geworden op: 17 mei 2006, 20:10
- Uitgedeelde bedankjes: 1057 keer
- Bedankt: 663 keer
-
Provider
Je hebt gelijk 
Ik had die landing page en ´t forum dooreen gehaald. Ik kijk er es naar of ik iets kan vinden...
Ik had die landing page en ´t forum dooreen gehaald. Ik kijk er es naar of ik iets kan vinden...
Telenet All-Internet -- using CV8560E & OPNsense on PCEngines APU2E4
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)
-
biot
- Starter Plus

- Berichten: 41
- Lid geworden op: 11 okt 2020, 14:03
- Uitgedeelde bedankjes: 3 keer
- Bedankt: 11 keer
[/reddit]
Wat hier misloopt is het resultaat van een dubbele conversie naar UTF-8.
De webserver geeft aan dat de HTML page UTF-8 is, via de header
In de linkse kolom zie je het woord correct; de "ï" zit ofwel in de database als UTF-8, of wordt correct omgezet naar UTF-8 voor het tonen. De UTF-8 code voor "ï" is 0xc3 0xaf (https://unicode-table.com/en/00EF/ -- zie tabel onderaan). In de rechtse kolom staat in plaats van "ï" de letters "ï", oftewel 0xc3 0x83 0xc2 0xaf.
Als je een "dubbele" UTF-8 conversie doet van die twee correcte UTF-8 bytes, is het resultaat 0xc3 0x83 0xc2 0xaf, dus dat is de oorzaak. Er zit dus een bug in de code die de rechtse kolom genereert.
Stukje Python dat het korter uitlegt:
Nee, specifiek niet. De screenshot bewijst het exact tegenovergestelde.devilkin schreef:Ik vrees dat dat aan jouw browser/instellingen zal liggen...
Wat hier misloopt is het resultaat van een dubbele conversie naar UTF-8.
De webserver geeft aan dat de HTML page UTF-8 is, via de header
Code: Selecteer alles
content-type: text/html; charset=UTF-8Als je een "dubbele" UTF-8 conversie doet van die twee correcte UTF-8 bytes, is het resultaat 0xc3 0x83 0xc2 0xaf, dus dat is de oorzaak. Er zit dus een bug in de code die de rechtse kolom genereert.
Stukje Python dat het korter uitlegt:
Code: Selecteer alles
>>> bytes('ï', 'utf-8')
b'\xc3\xaf'
>>> bytes('\xc3\xaf', 'utf-8')
b'\xc3\x83\xc2\xaf'
-
devilkin
- Administrator
- Berichten: 6909
- Lid geworden op: 17 mei 2006, 20:10
- Uitgedeelde bedankjes: 1057 keer
- Bedankt: 663 keer
-
Provider
Should be ok now.biot schreef:Ja, bedankt. Het probleem met deze topic, ook in de rechtse kolom (met die amp), is een gelijkaardig probleem, dubbele HTML entity encoding.devilkin schreef:Nu OK?
Telenet All-Internet -- using CV8560E & OPNsense on PCEngines APU2E4
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)
Proximus & Mobile Vikings -- Using OnePlus 8 Pro (ROM: Stock)